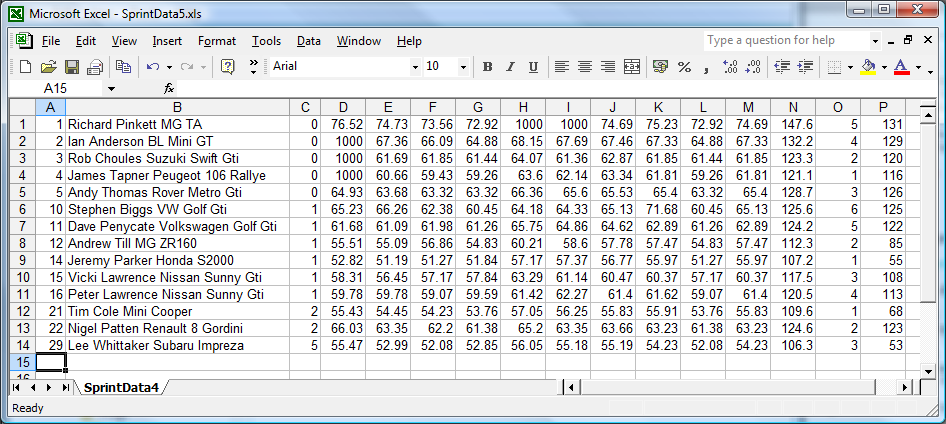
Overall, we have defined something less than the one click solution that we had in mind when we started. On the other hand, we have defined a scalable solution which does not take to much effort to execute. Most significantly it is much less tedious and particularly, it is free from potential random error. Systematic errors are easy to spot. Random errors, much less so. The algorithm also follows a general form which is often found in spreadsheet data. Columns of text on the left, columns of numbers on the right. Clearly every spreadsheet is different, and would require new expressions to be derived. Those that follow, or parts thereof, must surely feature in many such algorithms that solve similar problems.
These expressions have allowed us to get somthing that, at least on the face, appears to be a graphical image, into the cells of a spreadsheet.
We have seen how these expressions were defined, so it should be possible for you to follow those ideas, and develop your own.
The most important thing to take away from this is that regular expressions are not necassarily obvious, but they are understandable, and they are certainly better than the manual alternative. The best approach to solving such problems as this, is to experiment.
Start with your source data. Whenever you get a stage further forward, save your work to a new name. This ensures that you can go back if you notice a problem with an earlier stage when dealing with a later stage. Keep all the expressions that you use for a particular task in a text file. You can then go back and either reuse these expressions, or analyse them if you find afterwards that something was not quite right. To begin with, just experiment with search, rather than replace. It's a really great way to figure out what's wrong with your expression before actually trying to change things with it.
We hope that this example helps you to get the best from regular expressions. Regex is cryptic, but it's hugely powerful. It is very worthwhile spending the time to learn how to use them.