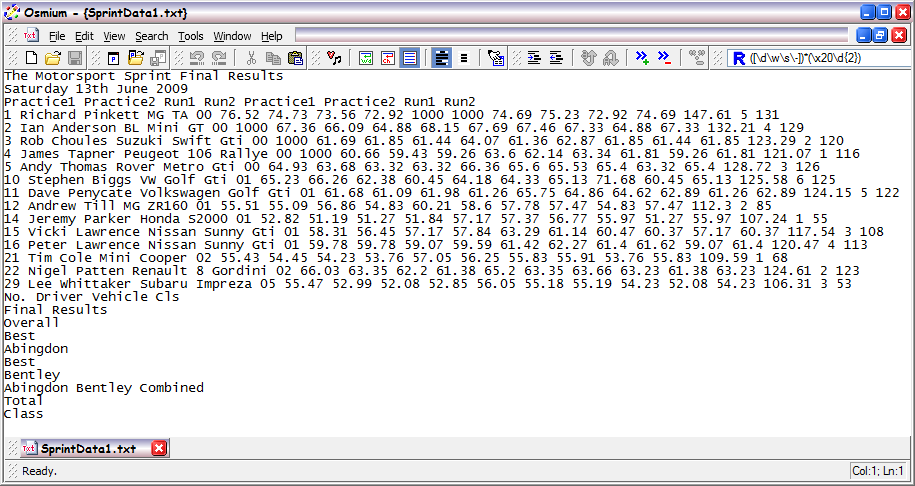
Having copied the data out of the Acrobat .pdf file we can now paste it, into Osmium as text. In Osmium we create a new text document with Ctrl +N,and paste the clipboard data into the new document with Ctrl + V.
As you can see the situation is not bad, but it's not ideal either. Fortunately it seems that the conversion from the original spreadsheet (the one we don't have) to .pdf, has maintained the order of the numeric and text data in the cells. It has not, however, maintained the header information in a logical form. By comparing with the original .pdf, we can see that some of the column headers from the top have been inserted at the bottom. This has occured because the original cells for this data were "merged cells". Fortunately, this data only occurs once in the document. Unlike the potential 150 rows of data, it's not too much trouble to transfer this data manually.
The column headers and footers we simply strip out, of our copied text data, leaving us with the following;