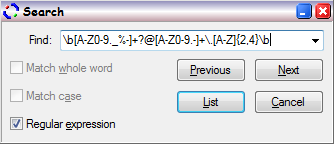
How to control the overal mode of a regular expression.
Regular Expressions Help Page
Regular expressions (regex) are a means of describing advanced text search parameters to a software program.
There is a wide variety of basic expression "languages", within those language groups there are often a variety of dialects. The Solid Fluid regular expression parser was written to the general form of the PCRE (Perl Compatible Regular Expression) dialect. Regex is such a flexible method of describing searches, and it's syntax so cryptic, it is very difficult to implement a perfect compatibility with another parser from scratch. In addition parsers themselves change, with development, over time. There are bound to be incompatibilities. Nevertheless, it is surprising how compatible all the common "grep style" regex parsers are.
Our regular expression parser is niether the most capable nor compatible. It does work, and it is useful. A quick reference guide is provided here. It is hoped that there is sufficient information to allow someone new to regex, the opportunity to grasp it's potential. If you are a seasoned hand with regex, there is certainly sufficient information to determine what our parser can and cannot do.
Regex operation
The regex parser operates on the basis of a search, and optionally a replacement, string. At the very top level the idea of the regular expression syntax is that for a simple search one can merely provide the search text, just as with an ordinary search. If you want to find the word dog in a large text file, then you simply type in the search term dog, just like you normally would.
Consider now the scenario that you wanted to find the words dig, dug or dog all in one search. This simply would not be possible with a standard search, and it is what regex has been designed to achieve. With regex, all you do is provide the search term d.g. The regex parser will interpret the period, as a wildcard, and find any middle character. Obviously this term has the potential to retrieve more words than intended, since dag is also a valid match for the search term d.g. Regex is much more capable than just allowing wildcards. Wildcards are, perhaps, it's most useful capability, even if no other capability is used. In this particular case the solution to the problem is to use the search term d(i|u|o)g, which will only match dig, dug or dog.
The details of why this last search term works, is not important for now, although you may already have guessed. The important thing to notice is that regex uses characters which you may actually wish to search for, and this initially seems a limitation. In addition to the basic mechanism where alphabetic and numeric characters represent themselves, there is also a scheme whereby it is possible to override the regex interpretation of the special characters, so that they may represent themselves in the actual search term.
In addition to the above functionality for describing searches, there is a tremendously important capability to do complex replacements. This scheme is actually very simple. The regex parser provides the ability for it's user to mark parts, or even the whole, of the regular expression, such that when a match is found the actual match text can be pasted into the replacement string, along with any other text you might wish to provide. It works, even when you specify wildcards in the search term. This aspect of regex is very important, because it allows processing of virtually any text file. A typical example of the usefulness of this scheme is where you have regular, but unformatted text that you need to import into, say, a spreadsheet. Rather than having to work through a file manually placing commas in just the right places to create a valid CSV file from the data, one may simply use regex to automate the process in just one click.
This spreadsheet import problem is, in fact, so ubiquitous we include a worked example here.
Definitions and terms
Throughout the reference we use specific terms. We also use hilights to indicate in the text which term is being discussed. Where a hilight is used we define it here with a description of it's meaning;
Expression text The text data with which one specifies the word, or character sequence, to find.
Result text The result text is part, or possibly the whole, of the search text found by the expression text.
Search text The source text data where one wishes to find a word, or character sequence.
Simple text In some cases, particular techniques that the regex parser uses as part of a whole expression, are unable to process regex commands in the usual way. In these situations simple text must be used, and this works in the same way as a normal search operation.
Token A regular expression is composed of tokens. A token is the unit of searching, a single character in the search text. Usually, but not always, a token would be represented by more than one character in the expression text.
Metatoken A metatoken behaves like a token in the expression text. Although a metatoken will usually have an associated "find" in the search text, it does not have a representative character in the result text.
Range A range is a group of alternative characters, which match to a single character in the result text. Because a range only represents a single charater in the result text, it is a type of token.
Group Groups in an expression behave like a token, but they are usually composed of more than one token. For this reason they can only be considered as tokens when they contain a single token. Because groups are usually composed of more than one token, they are represented by more than one character in the result text. Some types of groups force their contained tokens to become metatokens, and then the whole group has no representation in the result text.