 |
 |
 |
 |
 |
 |
|
2.1 Basic OperationAt the lowest level a sysmem block is merely a contiguous block of allocated data bytes. Sysmem is used within the VMM context to describe a large block of memory allocated from a higher level allocation suite. The term sysmem is a higher level concept than that of [heap]. VMM uses sysmem internally for a number of tasks, one of which is heap. In practice heap is the core of VMM, and it has functionality associated with it. The container class VHeap wraps a sysmem block and associates operators for manipulating “identities” within the sysmem block. These identities are elements in a linked list where each identity contains a fixed size header indicating the links and metadata and variable sized user data, usrmem. 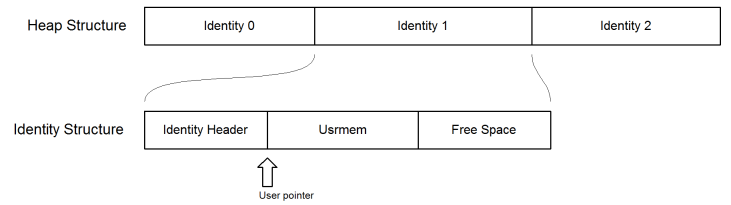 When memory is allocated a pointer is returned to the requester, and this pointer points to the start of the usrmem block which is also somewhere in the middle of the associated identity. The usrmem block contains the process or thread data. Where;
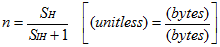 It has already been described that SH is variable, but typically an integer number of system pages. In practice the header size SIH is also variable. This primarily allows the optional inclusion of several debugging capabilities, the information for which resides in the header. This aspect is covered in greater detail later. The identities are contiguous. Whilst two allocated identities may be adjacent, two free identities shall not be adjacent. When the life of a usrmem block expires its identity shall always be merged with any free adjacent identity. To implement basic operations on the heap identity list, six operators were devised. These have been named (somewhat with tongue in cheek) after the elementary particles, but the analogy with Finnegans Wake is not entirely lost! The table below shows the operators provided by the VHeap wrapper. 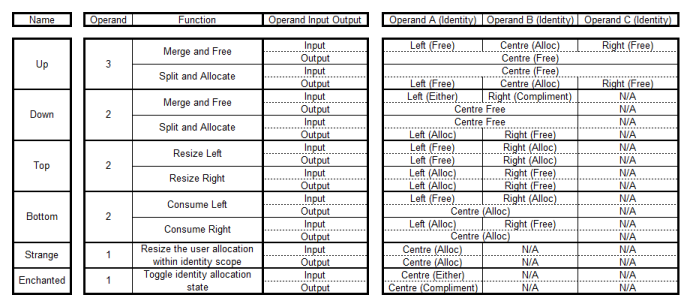 The table shows the variety of operators that are available for working on the heap. These functions are not called directly by the user, but VMM uses them as a result of user calls. If a free identity is very much greater in size than an optionally specified size, the Up function will be used to allocate the user memory from the middle of the free identity. This break size can be controlled by the user. If a free identity is smaller than the given size then the down function is used and the user memory is allocated from the left hand end of the free identity. This breakpoint capability is provided specifically to facilitate the resize operators. In an ideal situation every allocated identity would have free identity at each end, in order that a subsequent reallocation can merely grow the memory block into the adjacent memory. If memory is always allocated from one end of a free identity then there is never free space for the memory block to be “grown” into, and consequently a copy operation is required to physically move the expanded identity to a new location. This is a performance overhead which is to be avoided in order to improve the “gearing”. Notably it can be seen that the effect of fragmentation can actually help to improve the performance of the heap to the benefit of time at the cost of space. Clearly there comes a point where placing a new allocated identity into the centre of every free identity, leaves many small unusable fragments at each end. None is likely to be usable and in total can consume significant quantities of memory. This also is to be avoided. The down function is used to create new allocated identities from the left hand end of a free identity. Notably the Down function offers a split and allocate capability which can only allocate at the left hand end of a block. There is no complimentary function to allocate at the right hand end of a free block. The key reason is that allocating from the right hand end leaves no room for the new identity to grow in future, without a copy operation. In theory an identity could grow in a leftward direction, but it would have to be copied backwards, and this again would lead to a performance overhead. With a grow to the right, no copy operation is required since the base of the block does not move. It is arguable that placing a new allocated identity at the left of a free block will prevent the left adjacent allocated identity from growing. This is true, but the growth of either block cannot be predicted with certainty in advance. The final allocation scheme is to merely toggle a free identity into an allocated identity. This occurs for very small free identities, and the size [small break] is not available for control by the user, because its adjustment rarely yields performance benefit. In this scheme, the identity may contain less user data than it actually could contain. Growth of the user data within these identities can occur without time penalty, up to the capacity of the identity. Growth has previously covered both growth and reduction of any allocated identity. When considering reallocation the more advanced operators are required. In order to grow, an identity will first try to grow within its capacity, then into the right adjacent free identity if possible. Failing all of these the identity will be reallocated at the top level by VMM. In order to reduce, by small amounts, the identity will merely reduce its overall user allocation within. When the potential free space within an identity becomes larger than smallbreak, the identity is split into a free and allocated identity, with a preference for the free identity to be to the right. In the circumstance that there is a free identity to the left of the allocated one, but not to the right, then the new free identity will be manifest as a grow to the left hand free identity. This does involve a copy operation on the allocated block, but there is significant performance benefit in tending to maximise the size of free identities. At the very beginning of the passage, it was stated that “two free identities shall not be adjacent”. This is the lowest level rule. The remaining operators are used for the purpose of freeing allocated identities, to maintain that rule. The VHeap object could be used in a standalone capacity, but it can clearly be seen that there are inherent difficulties with maintaining the efficiency of the memory allocation process, merely as a result of the random nature of requests to the memory manager. An external compaction scheme was outlined earlier in this text, but it was shown that most normal environments lack the communications scheme to implement compaction. In theory, heap management could be made more efficient by a user communicating the intended use of a requested identity, specifically, an advance prediction for the range of sizes expected for the usrmem block. In practice allocation operations occur so regularly, that such communication would quickly become an overhead in its own right. Such a scheme is explicitly not offered to potential clients. A development scheme for testing and evaluation used VHeap as a standalone object. The linked identity list contained two parallel linkages. The first, a simple list of the whole content was maintained for integrity testing, the second reduced list contained only free identities within the heap. The intent was to improve performance of the heap by reducing the search dataset, particularly for allocation operations. Freeing an identity is relatively easy. Since VMM has a pointer to usrmem it is easy enough to calculate an offset to the start of the identity, where freeing the block is merely a case of using the operators to reference the old block and either free it or merge it with adjacent ones. Allocating an identity is harder. One has to find a suitable candidate as a free identity, and this can only be done by iterating the linked list. The larger the heap block is the greater the number of identities will be found. Often most are too small to be of use for a given request, and this can lead to an overhead, finding the candidate. Clearly the use of a secondary parallel “free linked list” helps, and whilst this is a suitable scheme for use in a test environment it is largely unsatisfactory for normal use. That sort of scheme is simply too slow for most processes, and especially the memory intensive ones. |


Copyright © Solid Fluid 2007-2025 |
Last modified: SolFlu Fri, 05 Jun 2009 22:32:39 GMT |