2.2 VFreeList & VFreeLUT
It has been seen that the VHeap object alone is insufficient to provide optimum performance from a system allocation resource. It is unlikely to be a surprise that the memory manager is capable of manipulating more than one heap object. In fact it is an essential capability to ensure that the capacity of the memory manager is only limited by the system memory resource.
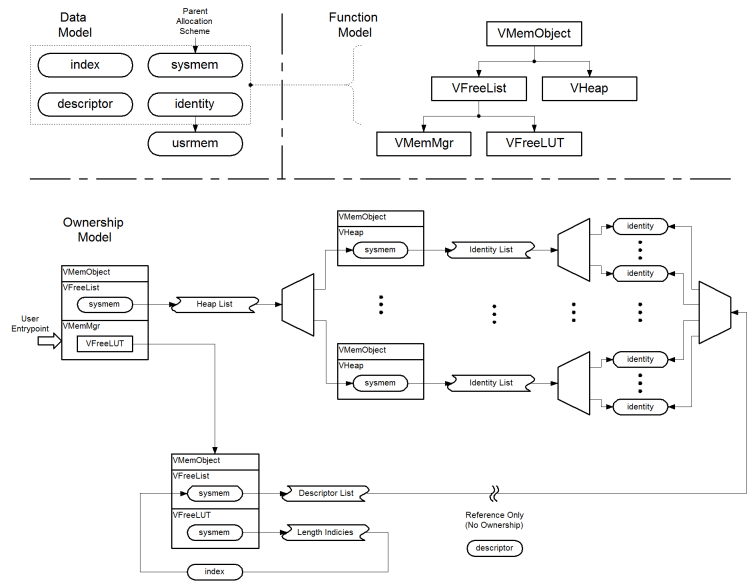
At the VMM level additional objects are provided to manage both the capability to manage multiple heap objects, and to speed up the process of finding a suitable candidate identity for an allocation request.
Clearly, when implementing a memory manager, one does not have a memory manager available to provide storage for the purpose of indexing and searching large quantities of data. To resolve this problem the module VFreeList is provided.
VFreeList is essentially a simplified memory manager. Details will follow but it provides storage for a resource limited (essentially infinite) number of fixed sized memory blocks. The size of these blocks is specified when the object is created. Clearly a scheme such as this is comparatively limited in terms of flexibility, since it may only deal with objects of the same type, or objects of different types that manifest as objects of the same size. For the purposes of VMM it performs two separate storage functions.
- Storage for the VHeap objects, within the memory manager.
- Storage of free identity descriptors.
To achieve this VFree list is inherited by both VMemMgr, and VFreeLUT.
VFreeLUT is an object which maintains a lookup table of free identity lengths, and references each to a linked list of free identity references [descriptors], where the identities all have that given length. At this stage the object relationships become more difficult to describe, but the diagram below illustrates the relationships.
The particular benefit of the VFreeLUT object is that it always maintains a global list of references to sized, free identities. Critically when an allocation of a given size is requested, the next identity of the requested size, or the nearest larger identity can quickly be found. This has a huge performance gain associated with it. Rather than iterating a list of free identities, and finding that most are simply too small, a search cycle is reduced to a single algorithmic operation.
A secondary benefit of this approach is that the iterative approach necessarily tends to choose identities that are significantly too big for the allocation request. Although such a “find” is functionally satisfactory, in practice it leads to heap fragmentation. The “sized” approach finds the most suitable identity, and not just and identity that has sufficient capacity to satisfy the request.
|